14 de outubro de 2024 08:32
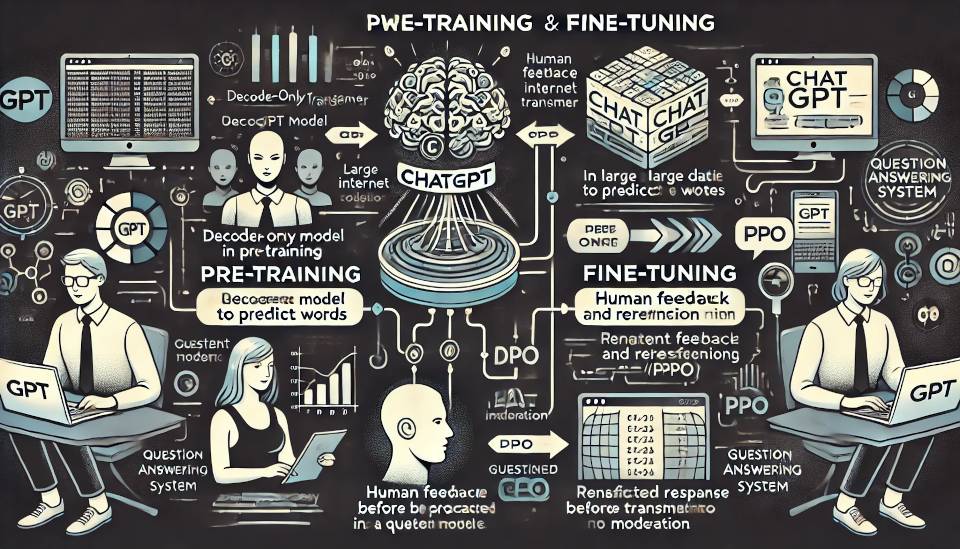
Entenda o Processo de Treinamento e Resposta.
Para treinar um modelo ChatGPT, existem duas etapas principais:
Pré-treinamento
Nesta etapa, treinamos um modelo GPT (um transformador de decodificação) com uma grande quantidade de dados da internet. O objetivo é treinar um modelo capaz de prever as próximas palavras em uma frase de forma gramaticalmente correta e semanticamente coerente, baseado em grandes volumes de dados da internet. Neste estágio, o treinamento é feito de forma não supervisionada, o que significa que o modelo aprende padrões linguísticos sem um objetivo específico, como responder a perguntas.
Ajuste fino
Esta etapa transforma o modelo pré-treinado em um modelo de perguntas e respostas como o ChatGPT, por meio de um processo de 3 passos:
- Coletar dados de treinamento (perguntas e respostas) e ajustar o modelo pré-treinado com esses dados. O modelo aprende a gerar respostas semelhantes aos exemplos fornecidos por seres humanos.
- Coletar mais dados (perguntas e várias respostas) e treinar um modelo de recompensa, que atribui pontuações às respostas, classificando-as da mais relevante para a menos relevante, com base em feedback humano.
- Usar aprendizado por reforço (otimização PPO) para refinar o modelo, tornando as respostas mais precisas e alinhadas às expectativas. O modelo é ajustado com base nas recompensas recebidas para melhorar sua precisão.
Responder a um prompt
Passo 1: O usuário digita uma pergunta completa, como “Explique como funciona um algoritmo de classificação”.
Passo 2: A pergunta é enviada para um componente de moderação de conteúdo, que garante que a pergunta não viole diretrizes de segurança e filtra perguntas inadequadas.
Passos 3-4: Se a entrada passar pela moderação, ela é enviada ao modelo ChatGPT para processamento. Caso contrário, a entrada vai diretamente para a geração de respostas genéricas e seguras.
Passos 5-6: Depois que o modelo gera a resposta, ela passa novamente pelo componente de moderação de conteúdo para garantir que seja segura, imparcial e apropriada.
Passo 7: Se a resposta passar pela moderação, ela é exibida ao usuário. Caso contrário, uma resposta padrão e segura é mostrada.