#gpt – Soluções WEB
O GPT (Generative Pre-trained Transformer) é uma série de modelos de IA desenvolvidos pela OpenAI, especializados em processamento de linguagem natural. Eles são conhecidos pela capacidade de gerar texto de alta qualidade, responder a perguntas, traduzir idiomas, entre outras tarefas. A evolução do GPT trouxe melhorias substanciais em compreensão contextual e geração de texto coerente.
Principais Versões do GPT:
- GPT-1: Lançado em 2018, foi o primeiro modelo da série com 117 milhões de parâmetros. Demonstrou o poder da abordagem pré-treinada para tarefas de linguagem natural.
- GPT-2: Lançado em 2019, com 1,5 bilhões de parâmetros, impressionou pela capacidade de gerar texto coerente, mas causou preocupações de segurança devido ao seu potencial de uso indevido.
- GPT-3: Lançado em 2020, com 175 bilhões de parâmetros, trouxe um salto significativo na qualidade de geração de texto e compreensão de contexto, sendo utilizado em várias aplicações comerciais.
- GPT-4: A versão mais recente, lançada em 2023, aumentou ainda mais a capacidade de entender e gerar texto complexo, com maior precisão e controle em respostas específicas, além de oferecer suporte multimodal.
Benefícios do GPT:
- Geração de texto fluente e coerente, útil para uma ampla gama de aplicações, como redação, atendimento ao cliente e criação de conteúdo.
- Capacidade de entender contextos complexos, gerando respostas que se alinham ao que foi solicitado pelo usuário.
- Treinamento em grandes volumes de dados da internet, resultando em um amplo conhecimento de domínios variados.
- Suporte multimodal (no GPT-4), possibilitando o entendimento e geração de texto baseado em múltiplas fontes de informação, como texto e imagens.
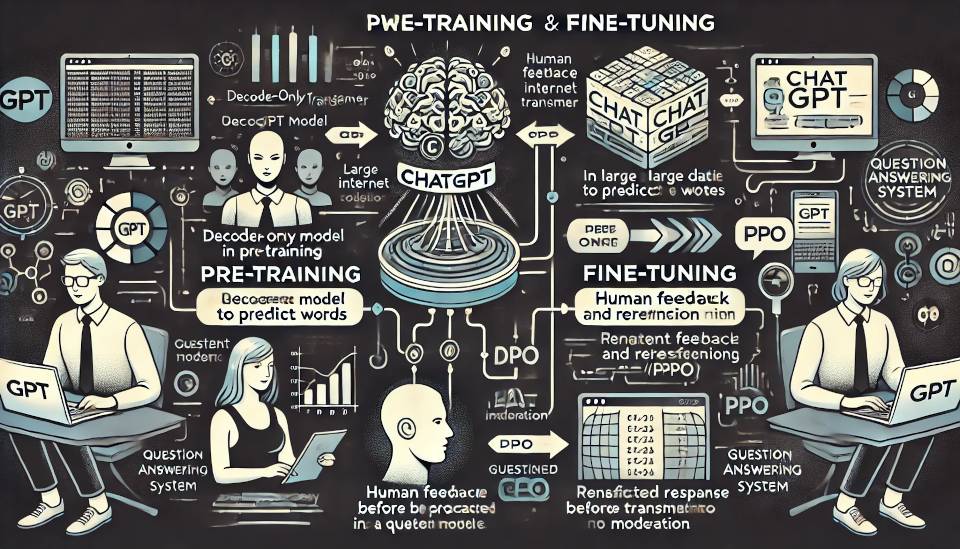
Ciclo de Vida de um Modelo GPT:
- Pré-treinamento: O modelo é pré-treinado em grandes quantidades de dados da internet para aprender padrões de linguagem.
- Ajuste Fino: Após o pré-treinamento, o modelo é ajustado em tarefas específicas para melhorar sua performance em determinadas aplicações.
- Utilização: O modelo é implementado em aplicativos que envolvem processamento de linguagem, como chatbots, assistentes virtuais e geradores de conteúdo.
- Atualizações e Melhorias: O modelo é continuamente atualizado com novos dados e técnicas de ajuste para melhorar sua precisão e capacidade de resposta.
Arquitetura do GPT:
- Transformador: O GPT é construído sobre a arquitetura de transformador, que utiliza mecanismos de atenção para processar texto de forma eficiente.
- Parâmetros: Cada versão do GPT possui um número crescente de parâmetros, que representam as conexões entre neurônios da rede neural. Aumentar os parâmetros melhora a capacidade do modelo de gerar texto mais coerente.
- Camadas: O GPT é composto por várias camadas de transformadores, onde cada uma refina o processamento do texto com base nas camadas anteriores.
- Multimodalidade: No GPT-4, o modelo também pode processar e gerar respostas baseadas em imagens e texto, oferecendo mais flexibilidade em aplicações.
Recursos e Aplicações:
- Redação de textos automáticos: Utilizado em geradores de conteúdo para blogs, redes sociais e jornais.
- Assistentes virtuais: Empregados em chatbots e assistentes pessoais para melhorar a interação humano-máquina.
- Tradução automática: Facilita a tradução de textos entre diversos idiomas de maneira fluida.
- Criação de código: Auxilia desenvolvedores na geração de código e na automação de tarefas repetitivas.
- Suporte ao cliente: Melhora o atendimento ao cliente automatizando respostas a perguntas frequentes.
- Suporte educacional: Utilizado como ferramenta para auxiliar no aprendizado e na criação de materiais educacionais personalizados.
News